*
- 住所録DBに、正規化したひらがな読みのレコードを追加
- 実際には、正規化したひらがなレコードにCSVデータの中の漢字氏名(1)、郵便番号(8), 住所1(9), 住所2(10) を付け足す
- 検索のさいには 慣例的なひらがなで検索する eg. 「いいづか」、「なかじま」 など。
- それを受け取って、正規化したひらがな「いいつか」「なかしま」を検索語として、DBの「正規化ひらがな」を検索
- 出力には、候補として中島、中嶋などを表示する
コード
#!/bin/bash
set -eu # Time-stamp: <2022-01-14 21:27:46 yamagami>
#
#
. func-define-normalization-rule.sh
. func-normalize-names.sh
#
define-normalization-rule
# 正規化された名前のひらがな読みをレコードとして含むデータファイル
data_file=./new-2k22.txt
#
read -rp '姓名(の一部)をひらがなで入力してください: ' keyin
# $keyinを正規化
normal_name=$(normalize-names "${keyin}")
# 検索
grep ${normal_name} ${data_file} > ./hit-list.txt
awk -F" " '{print $2, $3, $4, $5 $6}' ./hit-list.txt
きっかけ
- 年賀状宛名データが壊れて、修復した
- そのために郵便番号と住所を相互に検索できるツールを作り、出来上がった名簿データをチェックする際に、問題発生、
- よみのかな書きの表記ゆれがあって
。。。こんなのはどうでも良い?
- 細かいことは少しずつ書き足しますが、とりあえず要点だけをアップします。
正書法がない日本語
日本語一般に言えることだが、なかでも氏名の表記ってほんとうに無政府状態。
名前漢字に異字が多いこともそうだが、氏名のローマ字表記やひらがな(カタカナ)表記が自由奔放上代、ただしい書き方がなくて、もじどおりぐじゃぐじゃ。
これで不便をかこっている業界はたくさんあると思います。電話番号簿とか戸籍とかに始まり、同窓会名簿などでも、ちゃんとしたよみ仮名の正書法があれば、ミスが少なくり情報化を進めることができます。
個人の住所録(数百件程度)という小さなデータの中でも時として混乱が起きます。
ここでは、個人の住所録レベルのデータを念頭に、簡便な方法で姓名の読みのゆらぎを、抑える方法を紹介します。
その前に表記ゆれの出現頻度
表6は高橋・岩瀬(1992) による3,000万件の氏名データに基づく、表記ゆれの出現頻度。
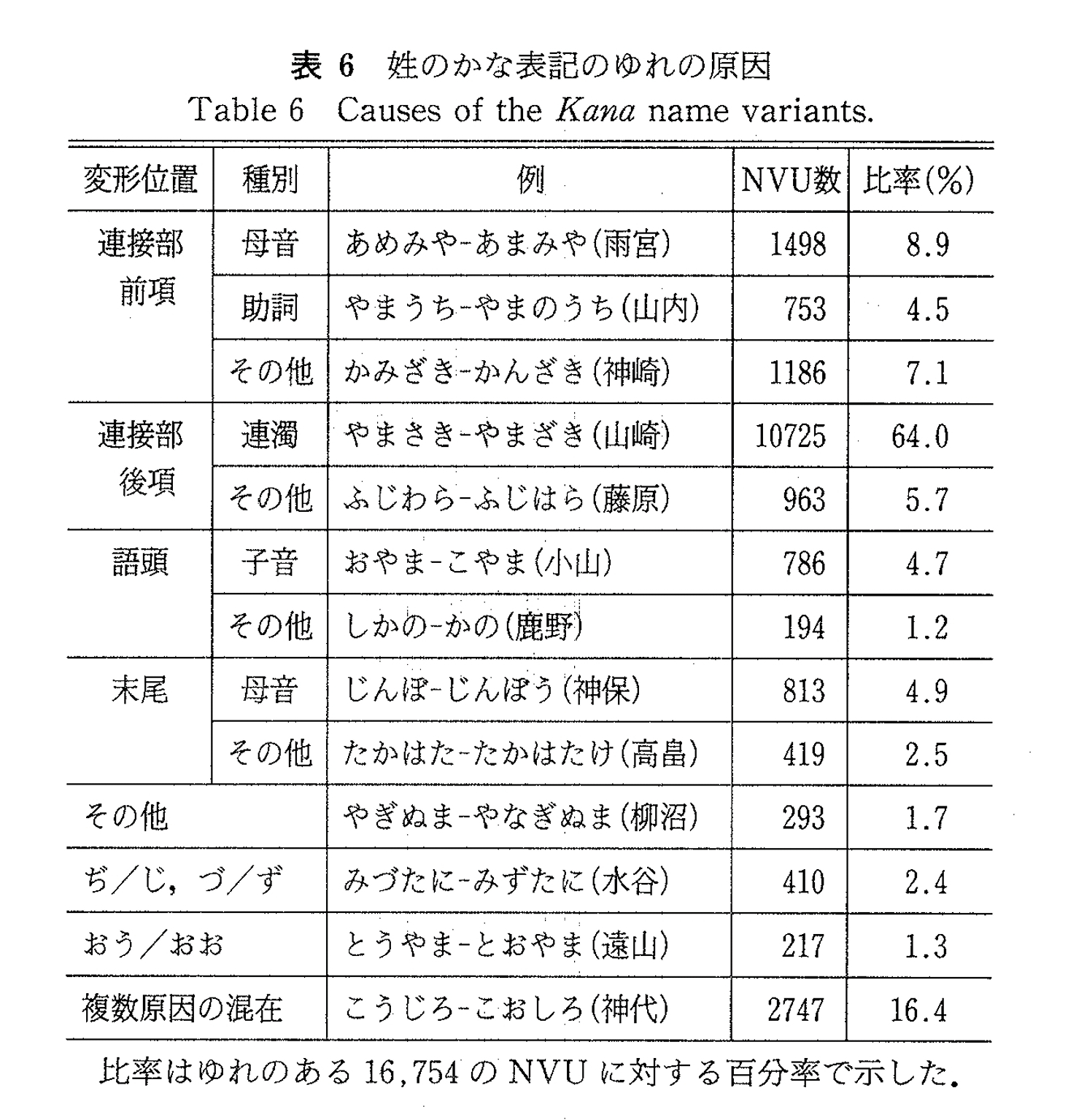
これによれば、「連接部・後項・連濁」によるゆれが64.0% で最大。つぎが「連接部前項・母音」が8.9%。「ぢ/じ、づ/ず」が2.4%, 「おう/おお」が1.3%
自家用の表記ゆれ防止の設計ポリシイ
表記ゆれバスター
もとより100パーセントのゆらぎ解決を目指すものではないので、とうめん
- 連濁 を解消
- つぎに「ぢ/じ、づ/ず」が2.4%, 「おう/おお」が1.3% などを解消することで
およそ65%はOKになる。残りの35%は、例外処理で手動のテンプレート=「ゆれの正規化規則」を作ればよい。という考え。
高橋克巳, 梅村恭司. (1995)に紹介されている電話番号案内におけるカナ表記のゆれ対策の例は次の通り。

以上を参考にしながら、
およそ65%はOKになる。残りの35%は、例外処理で手動のテンプレート=「ゆれの正規化規則」を作ればよい。
清濁混同
濁音をすべて清音に変換
- 「が・ざ・だ・ば行」を「か・さ・た・は行」に
- 半濁音「ぱぴぷぺぽ」はどうする? 人名に含まれているかしら? 「三平」とか「あんぽ」とかある。。。 これも全部清音化しよう。
sedで一発でできる see Bash sed:清音を濁音に変換
拗音・促音
- 小書きをすべて大書きに変換
これもsedで一発. see Bash sed:拗音・促音を大書きに
じ・ぢ & ず・づ混同
すべて「じ」「ず」に変換 sed 一発 =Bash sed: 「ぢづ」を「じず」に変換=
関数を2つ用意する
姓名かなのゆらぎの正規化ルールを定義する関数
define-normalization-rule
#!/bin/bash
#
# ひらがな姓名における ゆらぎ正規化ルールを定義する関数
#
function define-normalization-rule () {
#
################# 正規化テンプレート定義
# 例外定義 この下の定義で対処できないゆらぎを解消する例外処理
cat <<EOT>> "./reigai-1.sed"
s/づか/つか/
s/づき/つき/
EOT
# 小書き==> 大書き
cat << EOT >> "./kogaki2ogaki.sed"
y/ぃゃゅょゎっぁ/いやゆよわつあ/
EOT
# 「ぢづ」==> 「じず」へ
cat << EOT >> "./didu2jiju.sed"
y/ぢづ/じず/
EOT
# 濁音・半濁音を清音に
cat << EOT >> "./voiced2voiceless.sed"
y/がぎぐげご/かきくけこ/
y/ざじずぜぞ/さしすせそ/
y/だでど/たてと/
y/ばびぶべぼ/はひふへほ/
y/ぱぴぷぺぽ/はひふへほ/
EOT
}
上のルールを使って姓名よみのゆらぎを正規化する関数
normalize-names
#!/bin/bash
set -eu # Time-stamp: <2022-01-14 16:39:21 yamagami>
#
# 姓名の読み方のゆらぎを(出来る範囲内で)抑えるために
# 姓名を正規化normalizeする関数
# 引数は1つだけ、ひらがなの姓名1行
#
function normalize-names (){
# まずは例外から
echo $1 | sed -f ./reigai-1.sed > ./tmp-reigai.out
# 拗音・促音==> 大書き
sed -f ./kogaki2ogaki.sed ./tmp-reigai.out > ./tmp-oogaki.out
# 「ぢづ」==> 「じず」
sed -f ./didu2jiju.sed ./tmp-oogaki.out > ./tmp-didu.out
# 濁音・半濁音==> 清音
sed -f ./voiced2voiceless.sed ./tmp-didu.out > ./tmp-seion.out
#
cp ./tmp-seion.out tmp-final.out
cat ./tmp-final.out
#
#rm ./tmp-reigai.out ./tmp-didu.out ./tmp-seion.out ./tmp-oogaki.out
}
関数の使い方サンプル
準備
- 住所録DBに、正規化したひらがな読みのレコードを追加
- 実際には、正規化したひらがなレコードにCSVデータの中の漢字氏名(1)、郵便番号(8), 住所1(9), 住所2(10) を付け足す
よみの入力を正規化し、上のデータから検索する
- 検索のさいには 慣例的なひらがなで検索する eg. 「いいづか」、「なかじま」 など。
- それを受け取って、正規化したひらがな「いいつか」「なかしま」を検索語として、DBの「正規化ひらがな」を検索
- 出力には、候補として中島、中嶋などを表示する
コード
#!/bin/bash
#
. func-define-normalization-rule.sh
. func-normalize-names.sh
#
define-normalization-rule
# 正規化された名前のひらがな読みをレコードとして含むデータファイル
data_file=./new-2k22.txt
#
read -rp '姓名(の一部)をひらがなで入力してください: ' keyin
# $keyinを正規化
normal_name=$(normalize-names "${keyin}")
# 検索
grep ${normal_name} ${data_file} > ./hit-list.txt
awk -F" " '{print $2, $3, $4, $5 $6}' ./hit-list.txt
使用例
バッチ・一括変換
#!/bin/bash
#
# 姓名のひらがな表記のゆらぎを正規化する関数を呼ぶ スクリプト例
# =バッチ・一括的にファイル内からひらがな姓名を呼び出し正規化する用例
#
. func-define-normalization-rule.sh # ゆらぎ正規化ルールを定義する関数
. func-normalize-names.sh # ゆらぎを正規化する関数
# ひらがな姓名の正規化ルールを定義する
define-normalization-rule
##
#file_to_process="./sample.txt"
file_to_process="./hiragana-list.txt"
#
while read line
do
# 姓名よみのゆらぎを正規化する
normalize-names "${line}"
done < "${file_to_process}"
exit 0
サンプルデータ
sample.txt
いいづか いっぺい
こうづき ぽんた
かながわ ひょうた
なかじま ごんた
がまごおり ひゃくべえ
やまざき ごんべぃ
今後の問題=スルーした点
問題
- 清濁混同で濁音を先に直してしまうと、じず混同が効かなくなる。
- じず混同を直した後に、清濁混同を直すと「しす」になってしまう
- ので、「じず」だけは清濁混同から除外する必要がある
長音の混同
長音については、母音を重ねることを原則とするが
エ列のイ音、オ列のゥ音も長音に混同されやすいため、
エ列の長音とエ列のイ音、オ列の長音とオ列のウはそれぞれ
「イ」音と「ウ」音に正規化して処理する。すなわち
- エ列の後の長音「ー、イ、エ」→「イ」に正規化
- オ列の後の長音「ー、オ、ウ」→「ウ」に正規化
(例)
遠山:トウヤマ、トオヤマ、トーヤマ → トウヤマ
正規化のなかでこの中に含まれていなのは、「長音の正規化」

これがやっかい。例を上げると:
トウヤマ, トオヤマ
アンドウ, アンドー
サトウ, サトオ, サトー
ケイコ、ケーコ、ケエコ
正規化したとあるが、どうやったの?論文を見ると・・・

これをコードにするのは面倒
なので当面、スルーする。
その他

参考資料
References
人名|表記 | ゆれ
宮部博, 大山実, & 本郷郁夫. (1983).
名義検索システム-電話番号案内業務への適用.
情報処理学会論文誌, 24(4), 421-428.

戸部美春, 武藤信夫, & 山本康二. (1990).
高付加価値型番号案内システム (CUPID) の電話帳検索方式 (高付加価値型番号案内システム< 特集>).
NTT R & D, 39(6), p841-850. (インタ=ネット公開なし)
高橋克巳, & 岩瀬成人. (1992). 人名の読みからの検索法. 情報処理学会研究報告自然言語処理 (NL), 1992(74 (1992-NL-091)), 25-32. (https://ipsj.ixsq.nii.ac.jp/ej/index.php?active%5C_action=repository%5C_view%5C_main%5C_item%5C_detail&page%5C_id=13&block%5C_id=8&item%5C_id=13848&item_no=1)
高橋克巳, 梅村恭司. (1995). 人名のかな表記のゆれに基づく近似文字列照合法. 情報処理学会論文誌 8, 1906 - 1915. https://ipsj.ixsq.nii.ac.jp/ej/index.php?active%5C_action=repository%5C_view%5C_main%5C_item%5C_detail&page%5C_id=13&block%5C_id=8&item%5C_id=13848&item_no=1
横尾昭男, 宮崎正弘, 池原悟, 白井論, & 阿部さつき. (1997). 日英機械翻訳のための単語辞書. 情報処理学会研究報告自然言語処理 (NL), 1997(69dl.dropboxusercontent.com (1997-NL-120)), 37-44. https://ipsj.ixsq.nii.ac.jp/ej/?action=pages%5C_view%5C_main&active%5C_action=repository%5C_view%5C_main%5C_item%5C_detail&item%5C_id=48957&item%5C_no=1&page%5C_id=13&block_id=8
</home/yamagami/ダウンロード/IPSJ-JNL2404005.pdf>