概要
携帯電話(ガラケー)、Google Contacts、年賀状ソフト(筆王)など、あちこちに散在している氏名・連絡先データを「名寄せ」して一本化し、PostgreSQLのテーブルにしてちゃんと管理・運用してみようという企画。
データ件数は500件ほどです。小規模で個人的な住所録の整理整頓した作業メモです。
方針
- 出来上がったPostgreSQLターブルからのデータ抽出をどうするかの方針を立てる
- 各種の氏名・連絡先データをCSVデータとしてエクスポート
- それぞれのCSVをクリーニング、整列、整形
- PostgreSQLのインストールと初期設定
- 一本化したCSVをPostgreSQLにエキスポート
- 検索・結果表示のフロントエンドをBashスクリプト化する
まずは検索サンプル
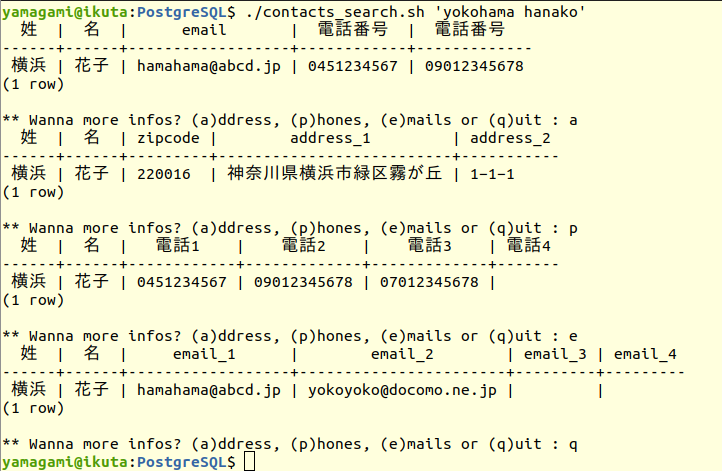
ごく簡単な検索・結果表示スクリプト ./contacts-search.sh を起動します。引数としてクエリ語(姓名、姓または名の一部)を入力。第1検索の結果表示は(当面)次の3情報です。
姓名(漢字)、Emailアドレスx1、電話番号x2
その下にさらに第2検索をやるかどうかのプロンプトが表示されます。
** Wanna more infos? (a)ddress, (e)mails, (p)hones, (r)e-select or (q)uit :
re-select を選ぶと別の検索に移れます。
サンプル画面
感想文
取りかかった当初は、たかが住所録、1週間もあれば余裕で終わると思っていました。しかし甘かった。
第一にハマったのはデータの洗浄・加工・整形。重複があるし、新旧が不明だし、タイポもある。また半角カタカナが混じっていたり、ダブルクオートでくくってあったり・・・。とんでもないカオスでした。
最大の問題は、日本語表記法の多様性というかブレの大きさ。そもそも、クエリ語を漢字、ひらがな、カタカナ、ローマ字のどれにすべきかで悩み、いろいろ試行錯誤しました。最終的には、ヘボン式ローマ字を使うことにしました。それには表記ブレのない姓名ローマ字表記が前提になります。
今回は大きな流れとしては次のようにしてローマ字姓名データを作りました。
- 姓名漢字から仮名読みデータをつくる(gmigemo)
- かな読みをヘボンローマ字に変換する(uconv)
- さらに細かくローマ字表記法を調整する(sed)
このローマ字姓名データを検索キーとしたPostgreSQL検索をBashスクリプト内に埋め込むことで、ターミナルから住所情報検索が簡単にできるようになりました。
姓名、姓または名(の一部でも可)をローマ字入力すると、あいまい検索の結果を得ます。
- まずはメールアドレスと電話番号を2つずつ表示する
- さらに詳細情報が必要ならば、「メールアドレス(最大5件)、電話番号(最大5件)、郵便番号と住所」
を選択表示できます。
原データのCSVテーブル整形・作成はBashでコツコツやりました。明らかに不要だと思われるデータは削除して残ったデータ件数は約500件でした。この程度の件数でも、csvtoolとかが無ければシェルスクリプトでやるのは無理だったと思います。
データがいったんPostgreSQL内におさまれば、あとの操作(編集、追加、削除など)はPostgreSQL内で楽にできます。やれやれ!です。