はじめに
4月はファーミングの準備期です。
この時期は種や苗の調達が大きな課題です。ジャガイモとかトマトの苗など、時期を外すと入手できなくなるものがあります。
プロの農家さんほどの品種数はありませんが、過去の購入履歴を、ぜんぶ覚えておくことはできません。同じ年内に購入済みの種をもう一度だぶって購入することもあります(笑)
Ledgerのトランザクションに次のような形で記録してあるので、データが無いわけではありません。
$ led print note サンマル --begin 01/01
2024/03/12 国華園
Expenses:Farming:種・苗 657 JPY
; サンマルツアーノ サニーレタス 玉レタス
Liabilities:OricoCard:seiji
しかしやっぱり作物の種と苗の購入日が一覧表になっている次のようなリストが欲しい!
:
イタリアンパセリ 2023/05/23
シシリアンルージュ 2023/05/23
早生枝豆 2023/05/26
湯上がり娘 2023/05/26
:
これをLedger内部で取得する方法があるのではないかと思いますがよく分かりません。
そこで
LedgerとBashシェルスクリプトを併用して試作することしました。いろいろな方法があるでしょうが、ここでは 連想配列 を使う方法をトライしました。
出力サンプル
図 1 は2024/01/01から本日までに購入した種・苗のリストです。
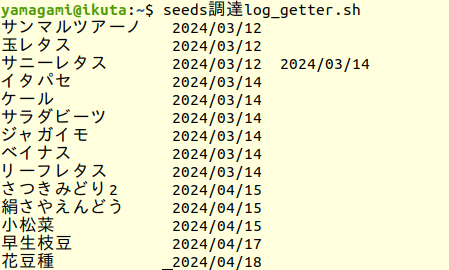
図1: サニーレタス購入日が2日あることに注目
処理の流れ
- 種・苗の購入に関係する Ledger-cli トランザクションの
print出力をファイル化 - 空行で区切りされているトランザクションブロックを1ブロックずつ読み込む
- そのブロックから、 日付 および 野菜名 (セミコロンの右側のリスト)を取得する
- 連想配列 seedsに、個々の野菜名を キー 、日付を 要素 として格納
- 連想配列 seedsを日付順にソートする
BashスクリプトのCode
スクリプト seeds調達log_getter.sh のコードには詳しいコメントをつけたので、見た目は長いですが実効行数はわずか 21行 。じっくりご覧になってもわずかな時間で読めます。
#!/bin/bash
#
# Ledgerコメント欄の種苗購入履歴を連想配列に格納しファイルに出力する
#
# (1) 勘定科目「farming:種・苗」 関係取引(TXN)を検索、txn-seeds.txt に格納
ledger print farming:種・苗 --begin 2024/01/01\
> txn-seeds.txt
# (2) 空行で区切られたTXNブロックの数を変数n_blocksに格納
# 最下行における空行有無への対応(=とりあえず削除しておいて n_blocks+=1
sed -i -z 's/\n$//' txn-seeds.txt
n_blocks=$(( $(awk '!NF {s+=1} END {print s}' txn-seeds.txt) +1))
# 配列宣言
declare -A seeds
declare -a veggie_list
# ここからメイン Loop
for i in $(seq 1 ${n_blocks}) ; do
# (3) 空行区切のTXNブロックを1つずつ読出しtmp-txt.datに書出す
awk -v RS= 'NR=='${i}'{ print }'\
< txn-seeds.txt\
> tmp-txn.dat
# (4) コメント行(;)を抽出し、日付と野菜名を取得して配列に格納
# (4)-1 変数dateに日付格納
date=$(grep -P '\d{4}/\d{2}/\d{2}' tmp-txn.dat \
| cut -d' ' -f1 )
# (4)-2 配列veggieに野菜名を格納
OLDIFS=$IFS
note_line=$(grep ';' ./tmp-txn.dat\
| nkf -Z1\
| sed 's/ *$//g'\
| sed 's/\;//g'\
| sed 's/x[0-9]//g'\
| sed 's/、/ /g'\
| sed 's/,//g'\
)
IFS=' ' read -ra veggie_list <<< "${note_line}"
IFS=$OLDIFS
# (4)-3 key=野菜名,value=日付を連想配列seedsに追記
# (同じ野菜の購入日が複数あるケースに対応 2024/04/21)
for veggie in "${veggie_list[@]}"; do
seeds[$veggie]="${seeds[$veggie]}${seeds[$veggie]:+,}$date"
done
done
# (5) 購入日(date)でソートしてseeds-buy-date.datに出力
for veggie in "${!seeds[@]}"; do
printf '%s, %s\n' $veggie ${seeds[$veggie]}
done | sort -k2 \
| column -t -s, \
> seeds-buy-date.dat
cat seeds-buy-date.dat
# (6) 一時ファイル削除
rm tmp-txn.dat txn-seeds.txt
exit 0
補足説明
野菜名をキーとし日付を要素にして連想配列 seedsに格納するパート((4)-3)について自分への備忘の意味でメモしておきます。
最初は次のようにコーディングしていました。
for veggie in "${veggie_list[@]}"; do
seeds+=(["${veggie}"]="${date}")
done
これがもっとも一般的な書き方だと思います。
しかしこれでは、上の出力例の「サニーレタス」のように、同じ野菜の種を購入した日が複数あるときには不都合が起こります。03/12に入力されたサニーレタスは、03/14で入力された配列要素で 上書き されてしまいます。
それを防止するために、次のように 変数展開 を使ったコードにしています。
for veggie in "${veggie_list[@]}"; do
seeds[$veggie]="${seeds[$veggie]}${seeds[$veggie]:+,}$date"
done
これは Stackoverflow の記事=「associate multiple values for one key in array in bash 」を参考にしました。その「解説」には次のように書かれています:
saves each $value in array[$key] separated by ,:
・ ${array[$key]} save previous value(s) (if any).
・ ${array[$key]:+,} adds a , if there’s a previous value.
・ $value adds the new read value.
目からウロコ!この記事のおかげで助かりました。
今後の課題など
- トランザクション内にコメント行が2行以上あるケースには未対応です。
- コメント行内の野菜名の区切記号としては全角読点、全角スペース、半角コンマなどは
sedで個別対応していますが、他の記号はとりあえずスルーしています。 - 同日内に同じ野菜を複数セット購入したときには
x3などとポスティングしていますが、こうしたセット数は削除しています。 - 種・苗の名前にスペースが含まれるものには未対応です。